3.7 Flink Connector —— Kafka 的使用和源码分析
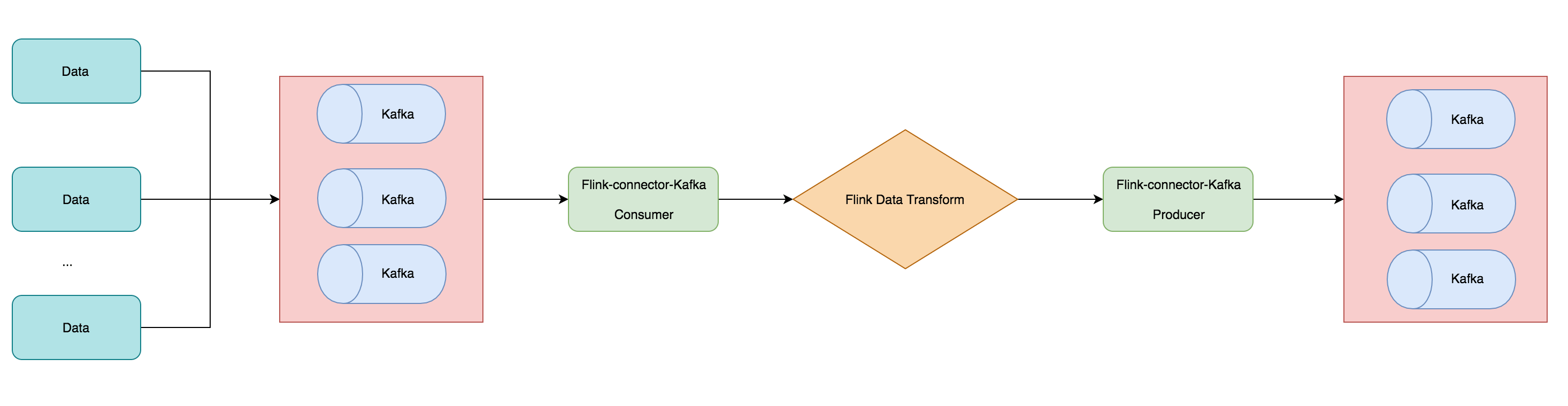
在前面 3.6 节中介绍了 Flink 中的 Data Source 和 Data Sink,然后还讲诉了自带的一些 Source 和 Sink 的 Connector。本篇文章将讲解一下用的最多的 Connector —— Kafka,带大家利用 Kafka Connector 读取 Kafka 数据,做一些计算操作后然后又通过 Kafka Connector 写入到 kafka 消息队列去,整个案例的执行流程如下图所示。
3.7.1 准备环境和依赖
接下来准备 Kafka 环境的安装和添加相关的依赖。
环境安装和启动
如果你已经安装好了 Flink 和 Kafka,那么接下来使用命令运行启动 Flink、Zookepeer、Kafka 就行了。
启动 Flink 的命令如下图所示:
启动 Kafka 的命令如下图所示:

执行命令都启动好了后就可以添加依赖了。
添加 Maven 依赖
Flink 里面支持 Kafka 0.8.x 以上的版本,具体采用哪个版本的 Maven 依赖需要根据安装的 Kafka 版本来确定。因为之前我们安装的 Kafka 是 1.1.0 版本,所以这里我们选择的 Kafka Connector 为 flink-connector-kafka-0.11_2.11 (支持 Kafka 0.11.x 版本及以上,该 Connector 支持 Kafka 事务消息传递,所以能保证 Exactly Once)。Flink Kafka Connector 支持的版本如下图所示:

添加如下依赖:
1
2
3
4
5
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
|
Flink、Kafka、Flink Kafka Connector 三者对应的版本可以根据 官网 的对比来选择。需要注意的是 flink-connector-kafka_2.11 这个版本支持的 Kafka 版本要大于 1.0.0,从 Flink 1.9 版本开始,它使用的是 Kafka 2.2.0 版本的客户端,虽然这些客户端会做向后兼容,但是建议还是按照官网约定的来规范使用 Connector 版本。另外你还要添加的依赖有:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
|
3.7.2 将测试数据发送到 Kafka Topic
我们模拟一些测试数据,然后将这些测试数据发到 Kafka Topic 中去,数据的结构如下:
1
2
3
4
5
6
7
8
9
| @Data
@AllArgsConstructor
@NoArgsConstructor
public class Metric {
public String name;
public long timestamp;
public Map<String, Object> fields;
public Map<String, String> tags;
}
|
往 kafka 中写数据工具类 KafkaUtils.java,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
public class KafkaUtils {
public static final String broker_list = "localhost:9092";
public static final String topic = "metric";
public static void writeToKafka() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<String, String>(props);
Metric metric = new Metric();
metric.setTimestamp(System.currentTimeMillis());
metric.setName("mem");
Map<String, String> tags = new HashMap<>();
Map<String, Object> fields = new HashMap<>();
tags.put("cluster", "zhisheng");
tags.put("host_ip", "101.147.022.106");
fields.put("used_percent", 90d);
fields.put("max", 27244873d);
fields.put("used", 17244873d);
fields.put("init", 27244873d);
metric.setTags(tags);
metric.setFields(fields);
ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, JSON.toJSONString(metric));
producer.send(record);
System.out.println("发送数据: " + JSON.toJSONString(metric));
producer.flush();
}
public static void main(String[] args) throws InterruptedException {
while (true) {
Thread.sleep(300);
writeToKafka();
}
}
}
|
运行结果如下图所示:
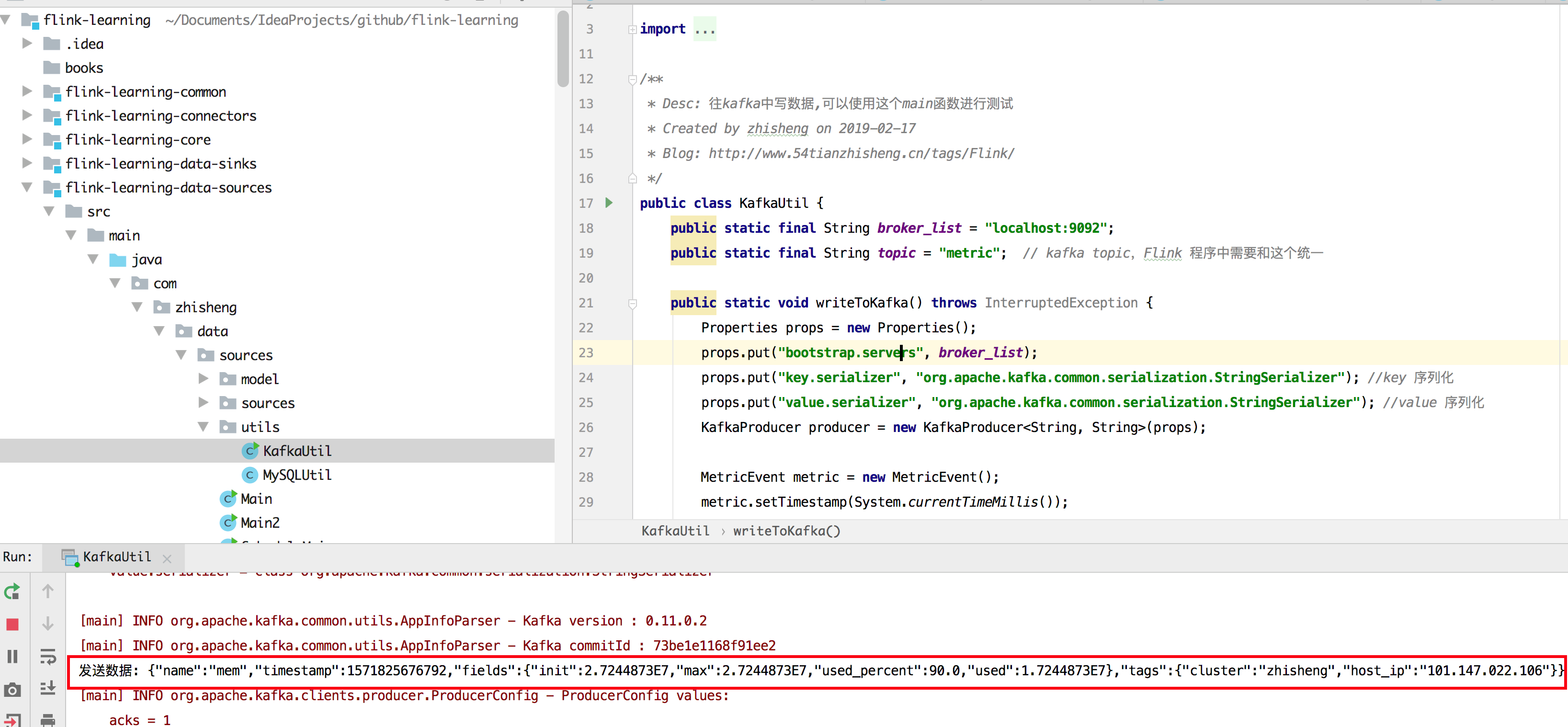
如果出现如上图标记的,即代表能够不断往 kafka 发送数据的。
3.7.3 Flink 如何消费 Kafka 数据?
Flink 消费 Kafka 数据的应用程序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
DataStreamSource<String> dataStreamSource = env.addSource(new FlinkKafkaConsumer011<>(
"metric",
new SimpleStringSchema(),
props)).setParallelism(1);
dataStreamSource.print();
env.execute("Flink add data source");
}
}
|
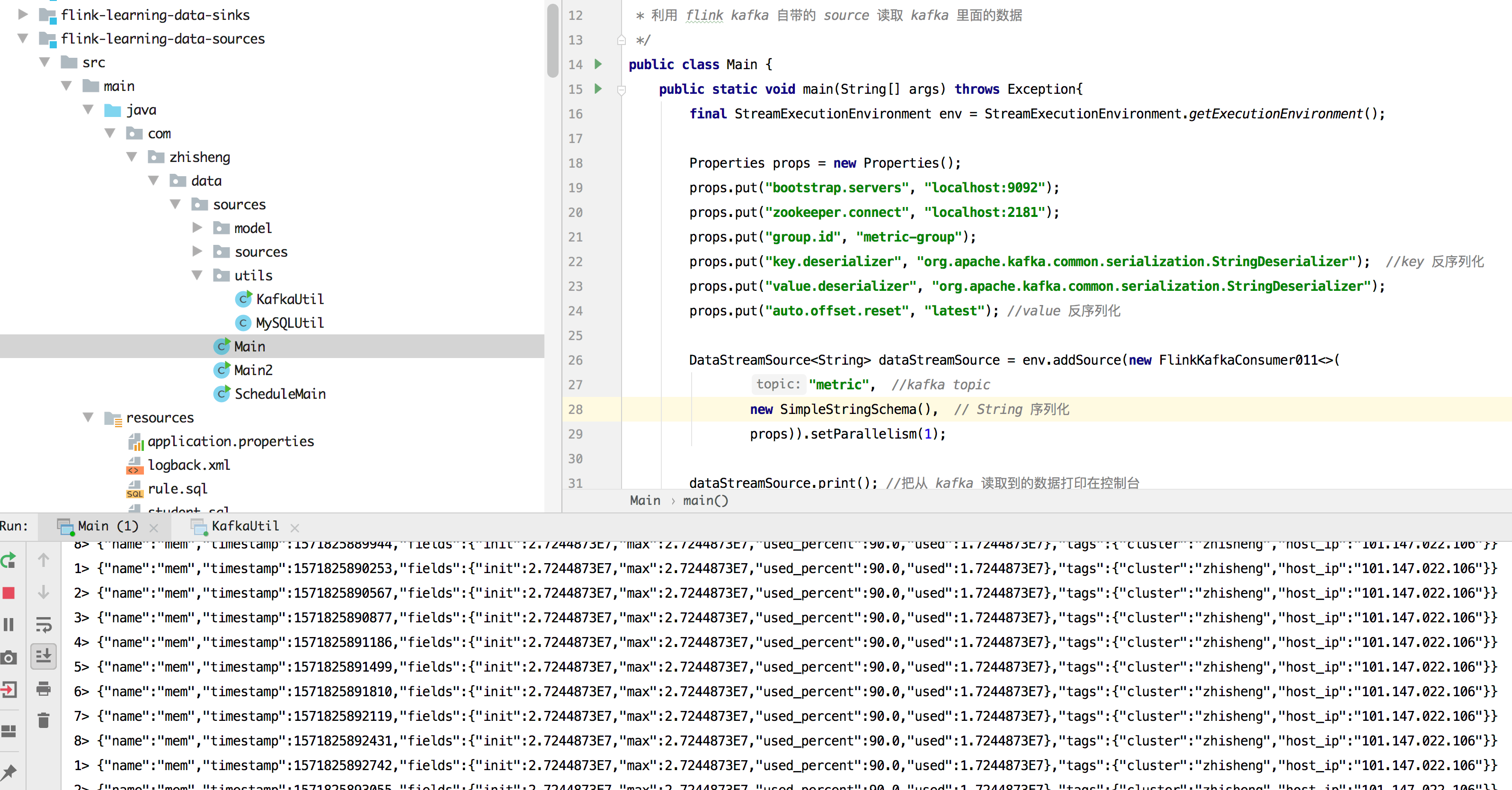
运行结果如下图所示(程序可以不断的消费到 Kafka Topic 中的数据):
代码分析
使用 FlinkKafkaConsumer011 时传入了三个参数:
- Kafka topic:这个代表了 Flink 要消费的是 Kafka 哪个 Topic,如果你要同时消费多个 Topic 的话,那么你可以传入一个 Topic List 进去,另外也支持正则表达式匹配 Topic,源码如下图所示。

前面演示了 Flink 如何消费 Kafak 数据,接下来演示如何把其他 Kafka 集群中 topic 数据原样写入到自己本地起的 Kafka 中去。
3.7.4 Flink 如何将计算后的数据发送到 Kafka?
将 Kafka 集群中 topic 数据写入本地 Kafka 的程序中要填写的配置有消费的 Kafka 集群地址、group.id、将数据写入 Kafka 的集群地址、topic 信息等,将所有的配置提取到配置文件中,如下所示。
1
2
3
4
5
6
7
8
9
10
11
| //其他 Kafka 集群配置
kafka.brokers=xxx:9092,xxx:9092,xxx:9092
kafka.group.id=metrics-group-test
kafka.zookeeper.connect=xxx:2181
metrics.topic=xxx
stream.parallelism=5
kafka.sink.brokers=localhost:9092
kafka.sink.topic=metric-test
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
stream.sink.parallelism=5
|
目前我们先看下本地 Kafka 是否有这个 metric-test topic 呢?需要执行下这个命令:
1
| bin/kafka-topics.sh --list --zookeeper localhost:2181
|
执行上面命令后的结果如下图所示:
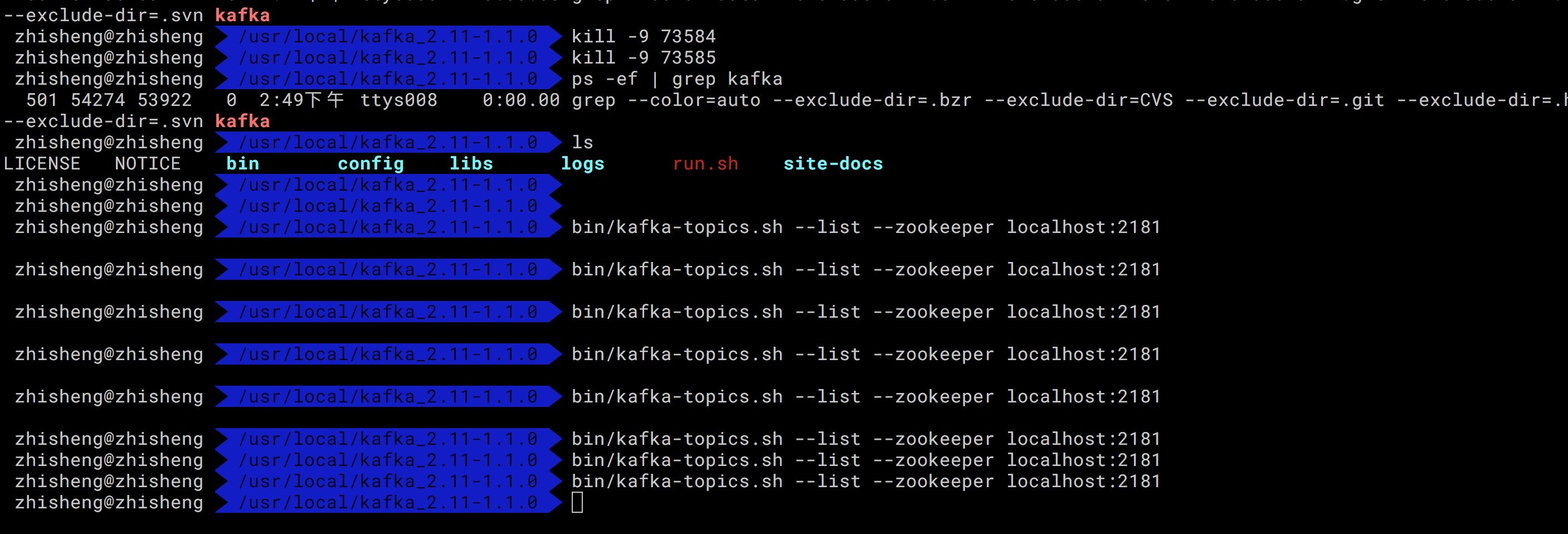
可以看到本地的 Kafka 是没有任何 topic 的,如果等下程序运行起来后,再次执行这个命令出现 metric-test topic,那么证明程序确实起作用了,已经将其他集群的 Kafka 数据写入到本地 Kafka 了。
整个 Flink 程序的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class Main {
public static void main(String[] args) throws Exception{
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
data.addSink(new FlinkKafkaProducer011<Metrics>(
parameterTool.get("kafka.sink.brokers"),
parameterTool.get("kafka.sink.topic"),
new MetricSchema()
)).name("flink-connectors-kafka")
.setParallelism(parameterTool.getInt("stream.sink.parallelism"));
env.execute("flink learning connectors kafka");
}
}
|
启动程序,查看运行结果,不断执行查看 topic 列表的命令,观察是否有新的 topic 出来,结果如下图所示:
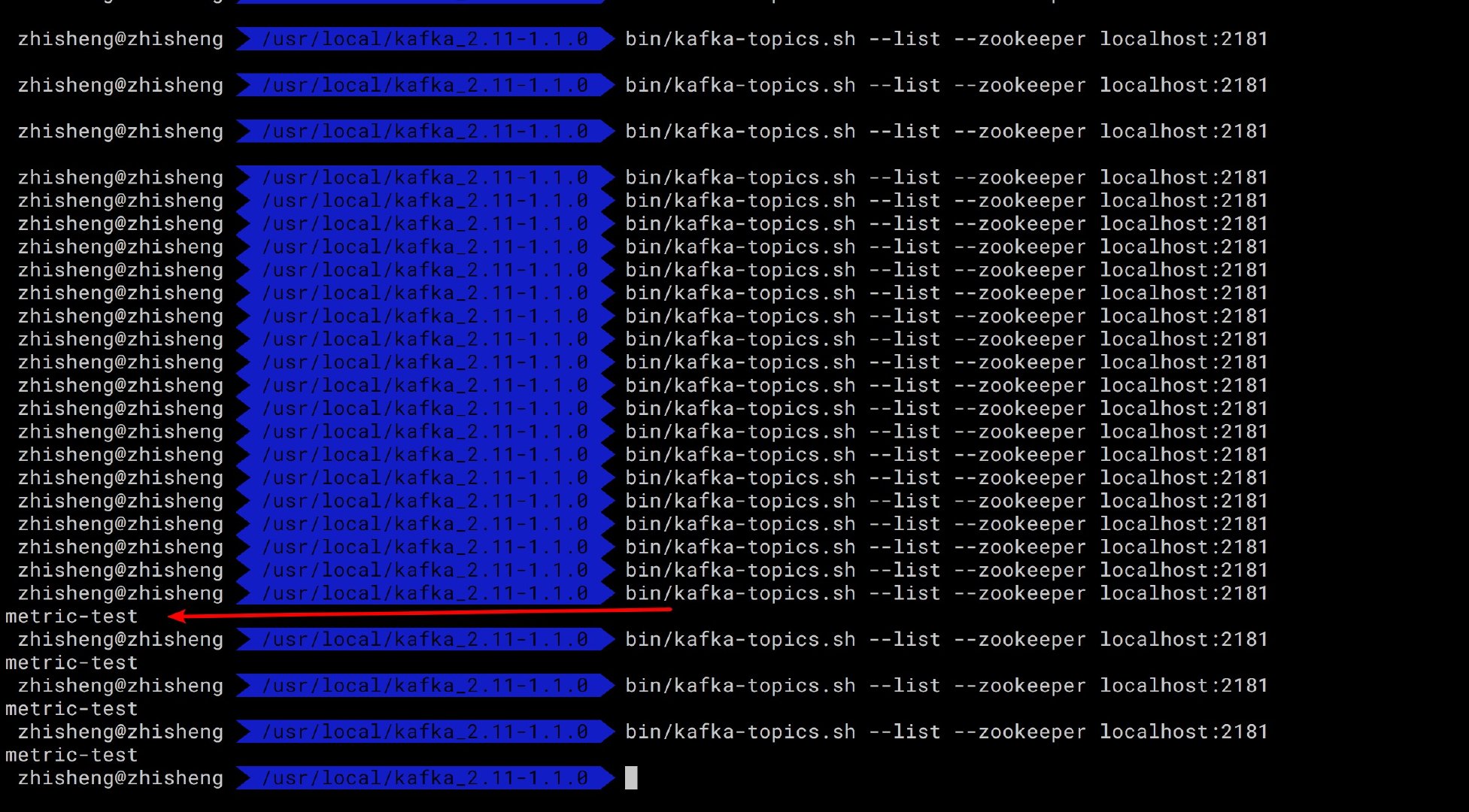
执行命令可以查看该 topic 的信息:
1
| bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic metric-test
|
该 topic 信息如下图所示:

前面代码使用的 FlinkKafkaProducer011 只传了三个参数:brokerList、topicId、serializationSchema(序列化),其实是支持传入多个参数的,Flink 中的源码如下图所示。

3.7.5 FlinkKafkaConsumer 源码分析
3.7.6 FlinkKafkaProducer 源码分析
3.7.7 使用 Flink-connector-kafka 可能会遇到的问题
如何消费多个 Kafka Topic
想要获取数据的元数据信息
多种数据类型
序列化失败
Kafka 消费 Offset 的选择
如何自动发现 Topic 新增的分区并读取数据
程序消费 Kafka 的 offset 是如何管理的
3.7.8 小结与反思
加入知识星球可以看到上面文章:https://t.zsxq.com/2bmurFy




