3.10 Flink Connector —— HBase 的用法 HBase 是一个分布式的、面向列的开源数据库,同样,很多公司也有使用该技术存储数据的,本节将对 HBase 做些简单的介绍,以及利用 Flink HBase Connector 读取 HBase 中的数据和写入数据到 HBase 中。
3.10.1 准备环境和依赖 下面分别讲解 HBase 的环境安装、配置、常用的命令操作以及添加项目需要的依赖。
HBase 安装 如果是苹果系统,可以使用 HomeBrew 命令安装:
HBase 最终会安装在路径 /usr/local/Cellar/hbase/ 下面,安装版本不同,文件名也不同。
配置 HBase 打开 libexec/conf/hbase-env.sh 修改里面的 JAVA_HOME:
1 2 # The java implementation to use. Java 1.7+ required. export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_152.jdk/Contents/Home"
根据你自己的 JAVA_HOME 来配置这个变量。
打开 libexec/conf/hbase-site.xml 配置 HBase 文件存储目录:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <configuration > <property > <name > hbase.rootdir</name > <value > file:///usr/local/var/hbase</value > </property > <property > <name > hbase.zookeeper.property.clientPort</name > <value > 2181</value > </property > <property > <name > hbase.zookeeper.property.dataDir</name > <value > /usr/local/var/zookeeper</value > </property > <property > <name > hbase.zookeeper.dns.interface</name > <value > lo0</value > </property > <property > <name > hbase.regionserver.dns.interface</name > <value > lo0</value > </property > <property > <name > hbase.master.dns.interface</name > <value > lo0</value > </property > </configuration >
运行 HBase 执行启动的命令:
执行后打印出来的日志如:
1 starting master, logging to /usr/local/var/log/hbase/hbase-zhisheng-master-zhisheng.out
验证是否安装成功 使用 jps 命令:
1 2 3 4 5 zhisheng@zhisheng /usr/local/Cellar/hbase/1.2.9/libexec jps 91302 HMaster 62535 RemoteMavenServer 1100 91471 Jps
出现 HMaster 说明安装运行成功。
启动 HBase Shell 执行下面命令:
运行结果如下图所示:
停止 HBase 执行下面的命令:
运行结果如下图所示:
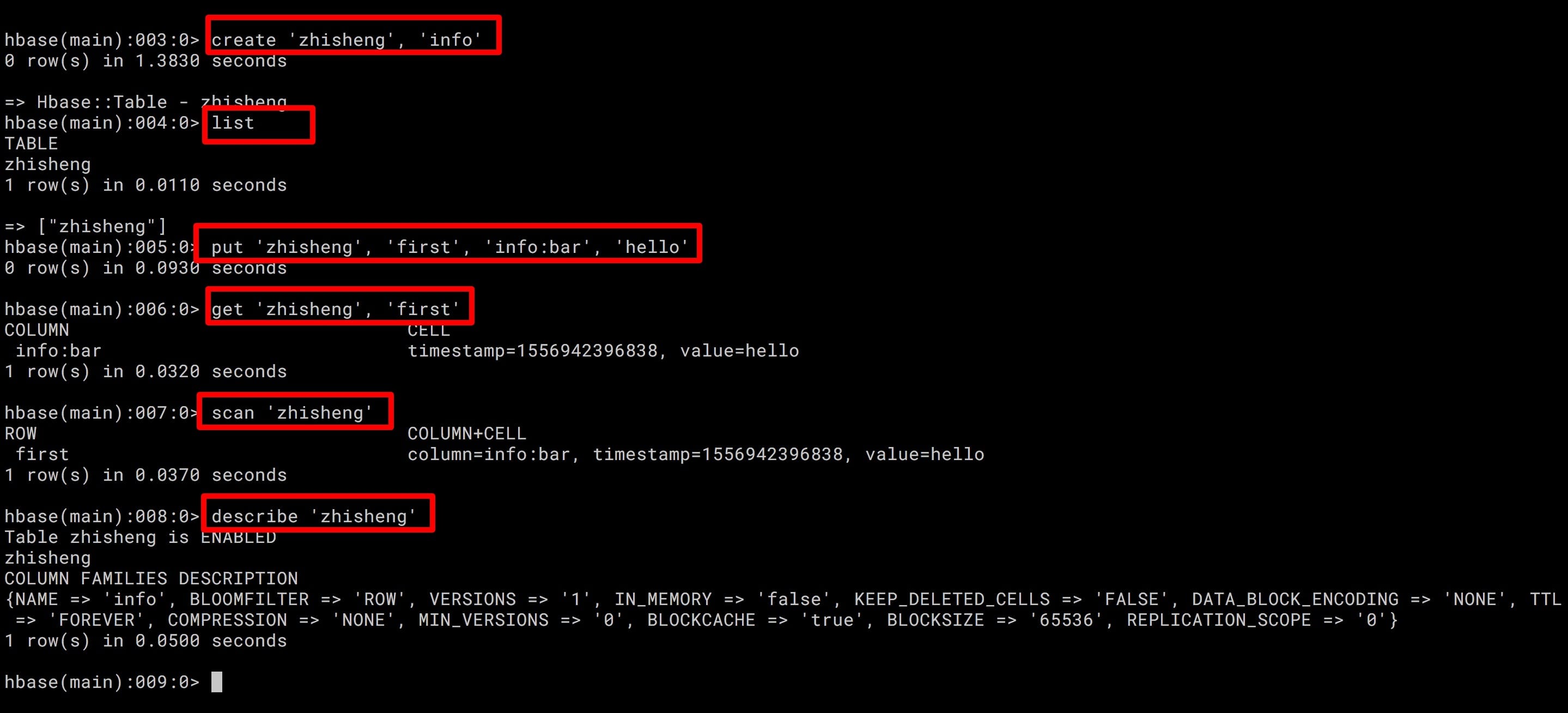
HBase 常用命令 HBase 中常用的命令有:list(列出已存在的表)、create(创建表)、put(写数据)、get(读数据)、scan(读数据,读全表)、describe(显示表详情),如下图所示。
简单使用上诉命令的结果如下:
添加依赖 在 pom.xml 中添加 HBase 相关的依赖:
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.apache.flink</groupId > <artifactId > flink-hbase_${scala.binary.version}</artifactId > <version > ${flink.version}</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.7.4</version > </dependency >
Flink HBase Connector 中,HBase 不仅可以作为数据源,也还可以写入数据到 HBase 中去,我们先来看看如何从 HBase 中读取数据。
这里我们使用 TableInputFormat 来读取 HBase 中的数据,首先准备数据。
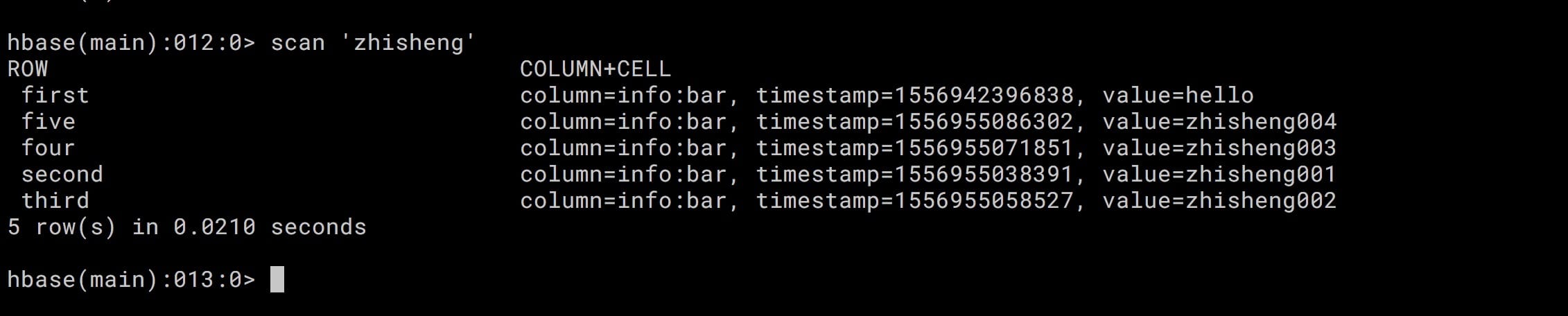
准备数据 先往 HBase 中插入五条数据如下:
1 2 3 4 5 put 'zhisheng', 'first', 'info:bar', 'hello' put 'zhisheng', 'second', 'info:bar', 'zhisheng001' put 'zhisheng', 'third', 'info:bar', 'zhisheng002' put 'zhisheng', 'four', 'info:bar', 'zhisheng003' put 'zhisheng', 'five', 'info:bar', 'zhisheng004'
scan 整个 zhisheng 表的话,有五条数据,运行结果如下图所示:
Flink Job 代码 Flink 读取 HBase 数据的程序代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class HBaseReadMain public static final String HBASE_TABLE_NAME = "zhisheng" ; static final byte [] INFO = "info" .getBytes(ConfigConstants.DEFAULT_CHARSET); static final byte [] BAR = "bar" .getBytes(ConfigConstants.DEFAULT_CHARSET); public static void main (String[] args) throws Exception ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.createInput(new TableInputFormat<Tuple2<String, String>>() { private Tuple2<String, String> reuse = new Tuple2<String, String>(); @Override protected Scan getScanner () Scan scan = new Scan(); scan.addColumn(INFO, BAR); return scan; } @Override protected String getTableName () return HBASE_TABLE_NAME; } @Override protected Tuple2<String, String> mapResultToTuple (Result result) String key = Bytes.toString(result.getRow()); String val = Bytes.toString(result.getValue(INFO, BAR)); reuse.setField(key, 0 ); reuse.setField(val, 1 ); return reuse; } }).filter(new FilterFunction<Tuple2<String, String>>() { @Override public boolean filter (Tuple2<String, String> value) throws Exception return value.f1.startsWith("zhisheng" ); } }).print(); } }
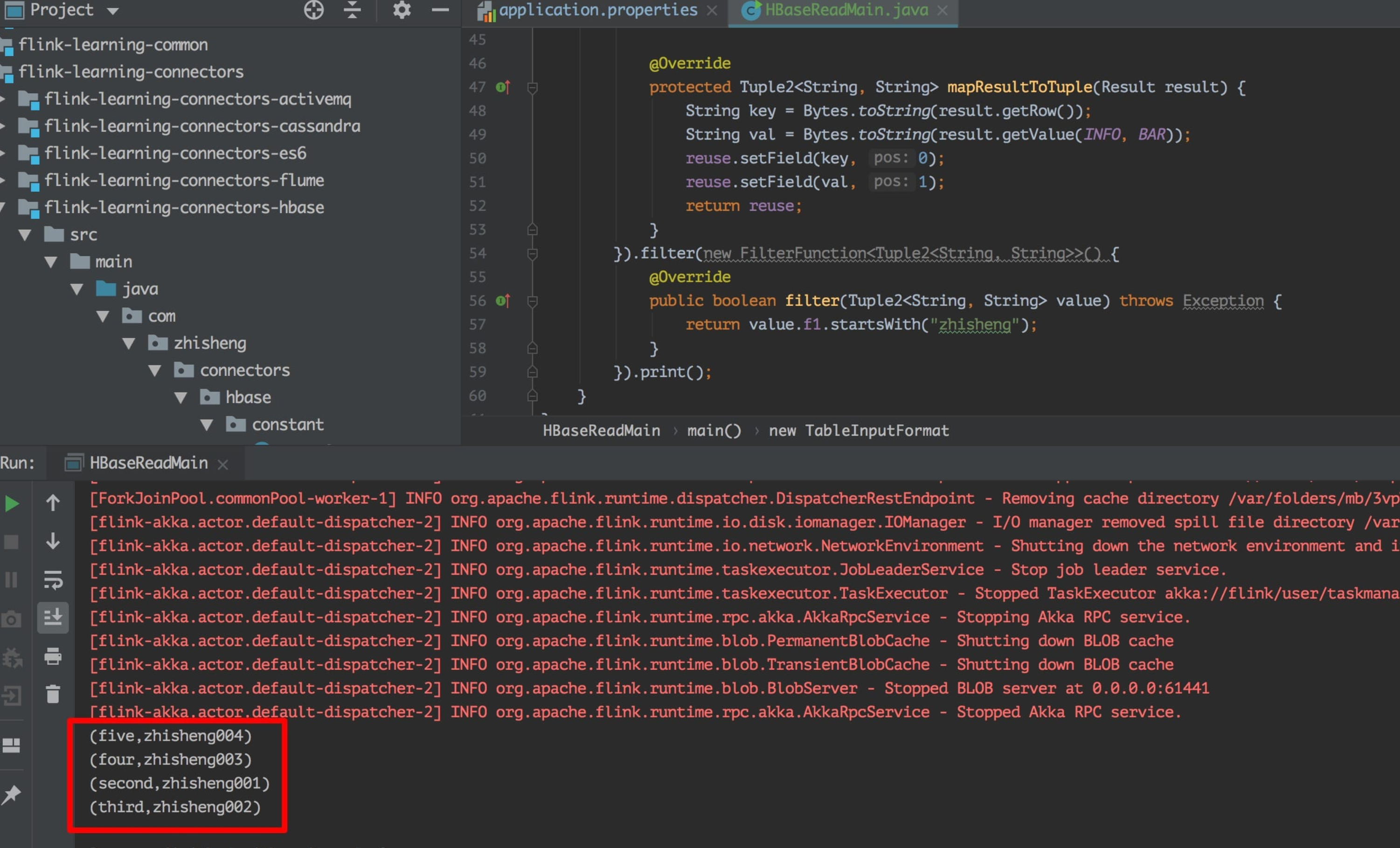
上面代码中将 HBase 中的读取全部读取出来后然后过滤以 zhisheng 开头的 value 数据。读取结果如下图所示:
可以看到输出的结果中已经将以 zhisheng 开头的四条数据都打印出来了。
添加依赖 Flink Job 代码 读取数据 写入数据 配置文件 3.10.5 项目运行及验证 3.10.6 小结与反思 加入知识星球可以看到上面文章:https://t.zsxq.com/3bimqBM