
管理小文件
许多用户关注小文件问题,可能导致以下情况:
- 稳定性问题:HDFS 中如果存在太多小文件的话会导致 NameNode 压力过大
- 成本问题:在 HDFS 中,每个小文件都会占用至少一个数据块的大小,例如 128 MB
- 查询效率:查询过多小文件会影响查询效率
理解 Checkpoint
假设你正在使用 Flink Writer,每个 Checkpoint 会生成 1 ~ 2 个 snapshot,并且 Checkpoint 时会强制将文件生成在分布式文件系统(DFS)上,因此 Checkpoint 间隔越小,生成的小文件就越多。
1、所以先要增加 Checkpoint 间隔时间
默认情况下,不仅 Checkpoint 会生成文件,写入器(Writer)的内存(write-buffer-size)耗尽时也会将数据刷新到 DFS 并生成相应的文件。你可以启用 write-buffer-spillable 在写入器中生成溢出文件,以生成更大的文件在 DFS 上。
2、其次增加 write-buffer-size 或启用 write-buffer-spillable
理解 Snapshot
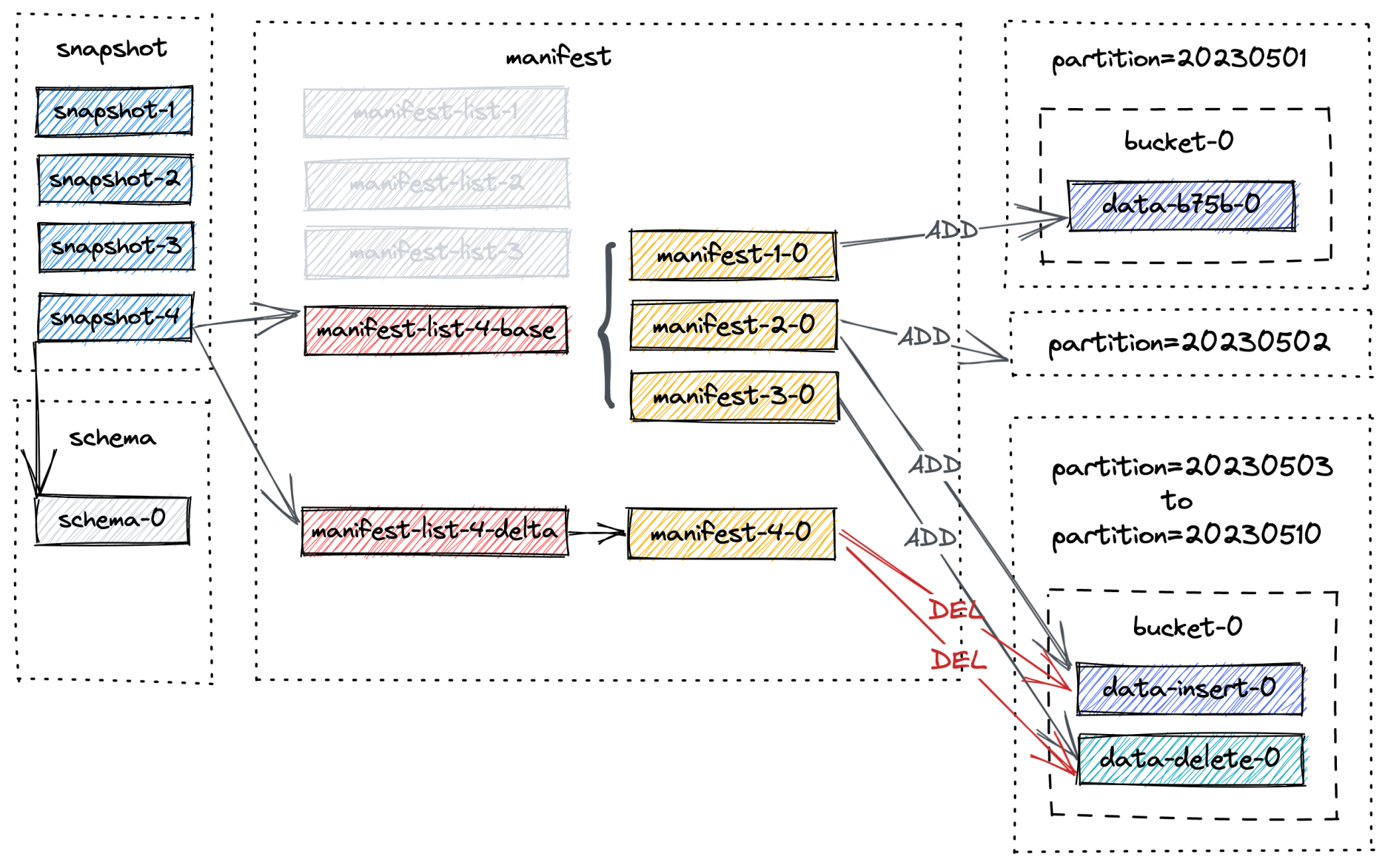
Paimon 维护文件的多个版本,文件的合并和删除是逻辑上的操作,并不实际删除文件。只有在 snapshot 过期时,文件才会真正被删除,所以减少文件的一种方法是缩短 snapshot 过期的时间。Flink Writer 会自动处理过期的 snapshot。
理解 分区 和 Buckets
Paimon 的文件以分层方式组织。下图展示了文件布局。从 snapshot 文件开始,Paimon 的读取器可以递归地访问表中的所有记录。
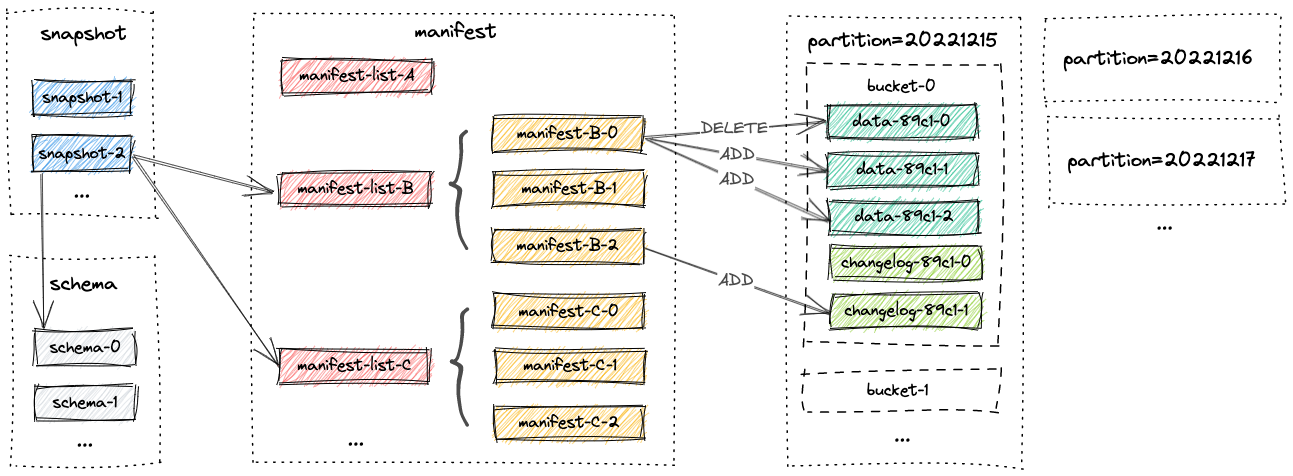
举个例子:
1 | CREATE TABLE MyTable ( |
表数据会被物理分片到不同的分区,里面有不同的 Bucket ,所以如果整体数据量太小,单个 Bucket 中至少有一个文件,建议你配置较少的 Bucket 数量,否则会出现也有很多小文件。
理解 Primary Table 的 LSM
LSM 树将文件组织成多个 sorted run。一个 sorted run 由一个或多个数据文件组成,每个数据文件都属于且仅属于一个 sorted run。
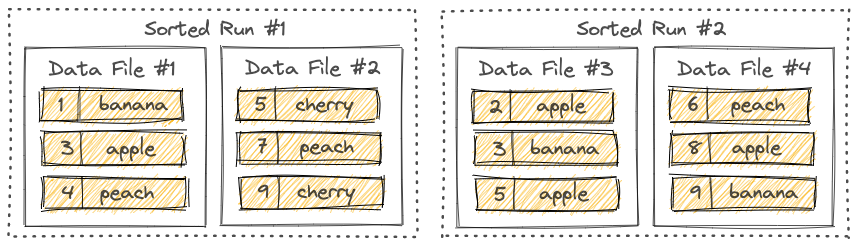
默认情况下,sorted run 的数量取决于 num-sorted-run.compaction-trigger 参数,这意味着一个Bucket 中至少有 5 个文件。如果你想减少这个数量,可以保留较少的文件,但写入性能可能会受到影响。如果该值变得过大,在查询表时会需要更多的内存和 CPU,这是写入性能和查询性能之间的权衡。
理解 Append-Only 表的文件
默认情况下 Append Only 表也会进行自动合并以减少小文件的数量。
然而,对于 Bucket 的 Append Only 表来说,它会出于顺序目的而只压缩 Bucket 内的文件,这可能会保留更多的小文件。
理解 Full Compaction
也许你认为 Primary Key 表中的 5 个文件还可以接受,但 Append Only 表(Bucket)可能在一个单独的 Bucket 中就会有 50 个小文件,这是很难接受的。更糟糕的是,不再活跃的分区也会保留这么多小文件。
建议你配置全量合并(Full-Compaction),通过设置 full-compaction.delta-commits参数,在Flink 写入过程中定期执行全量合并,这样可以确保在写入结束之前对分区进行完全合并。



