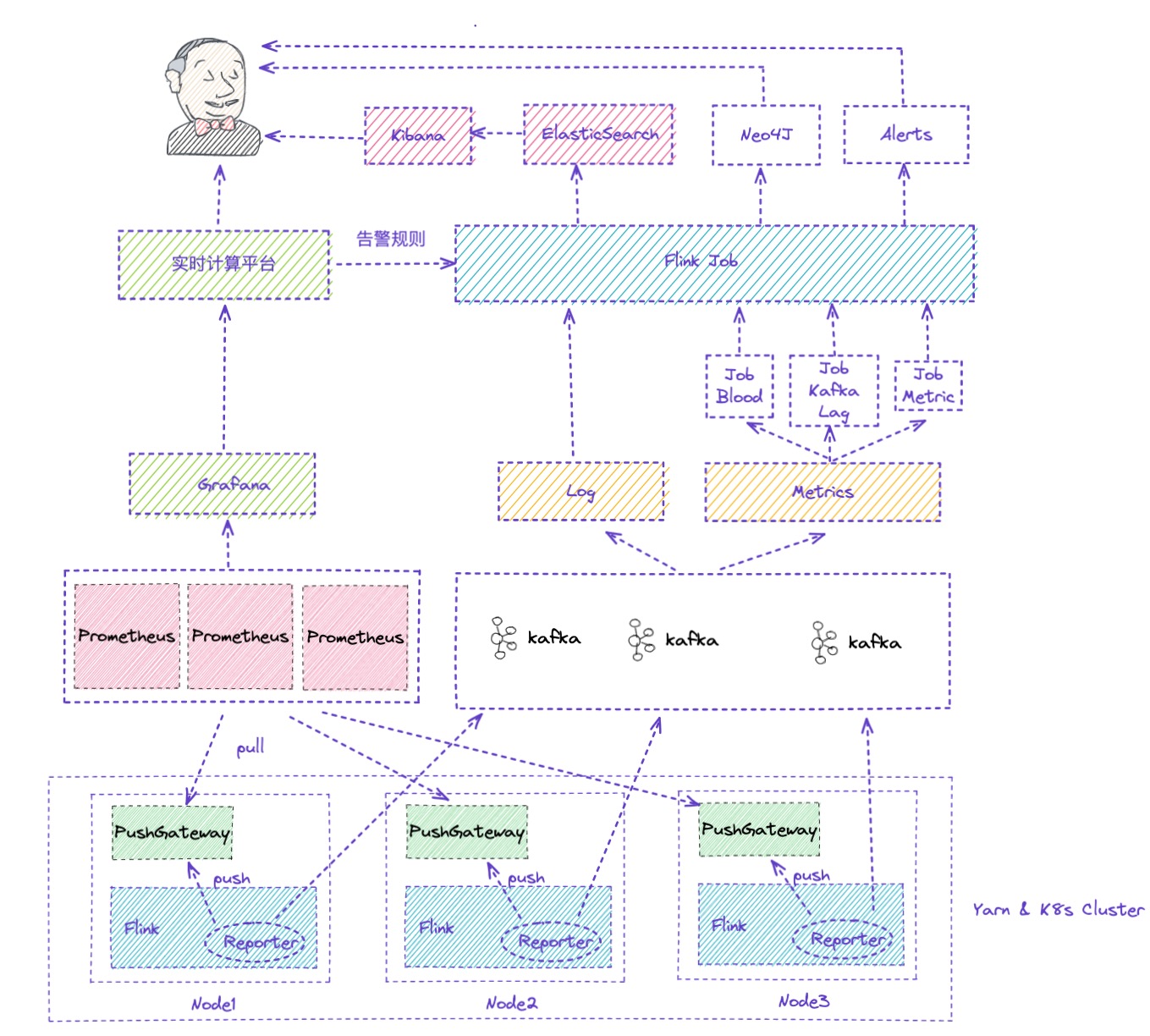
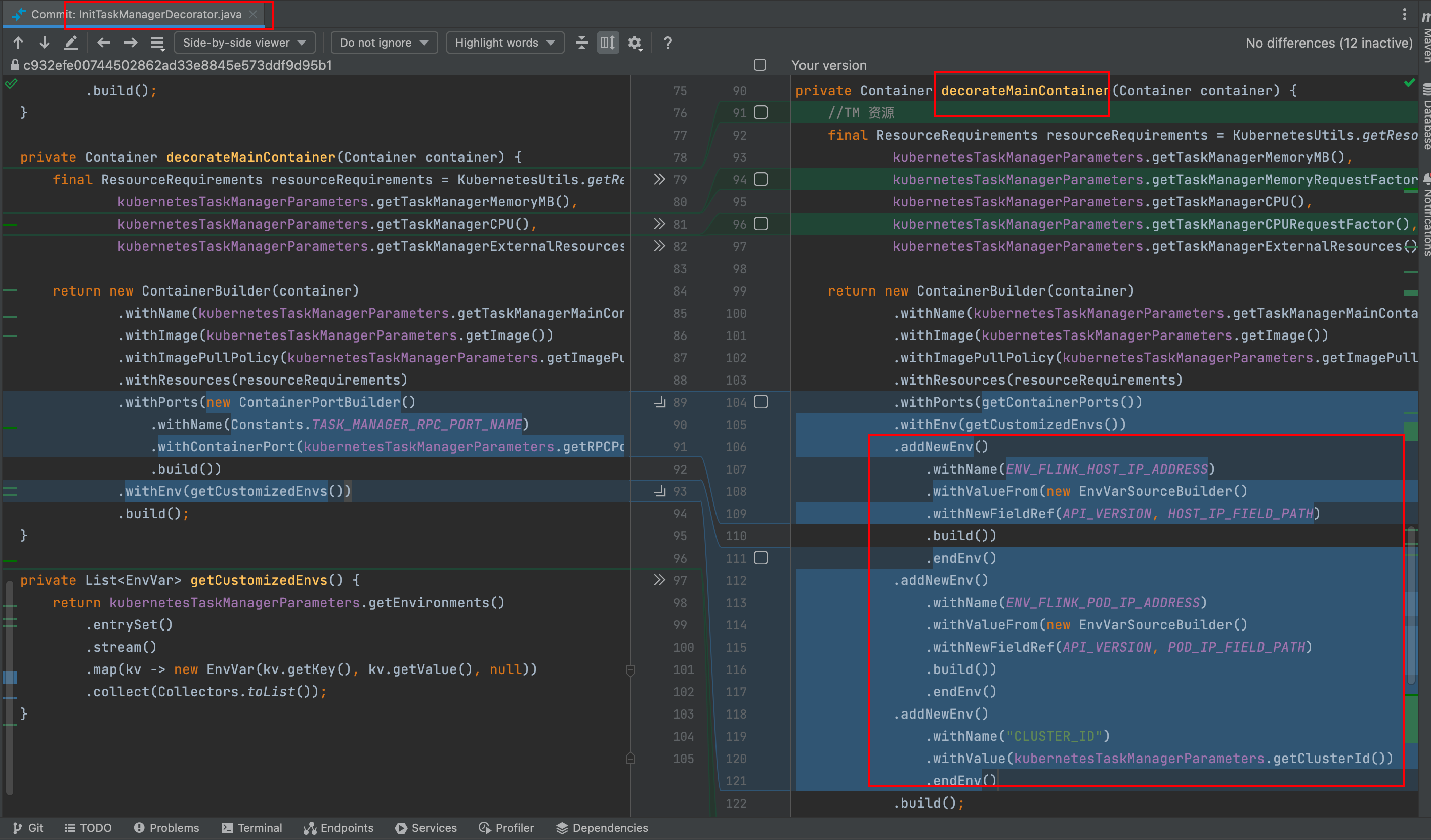
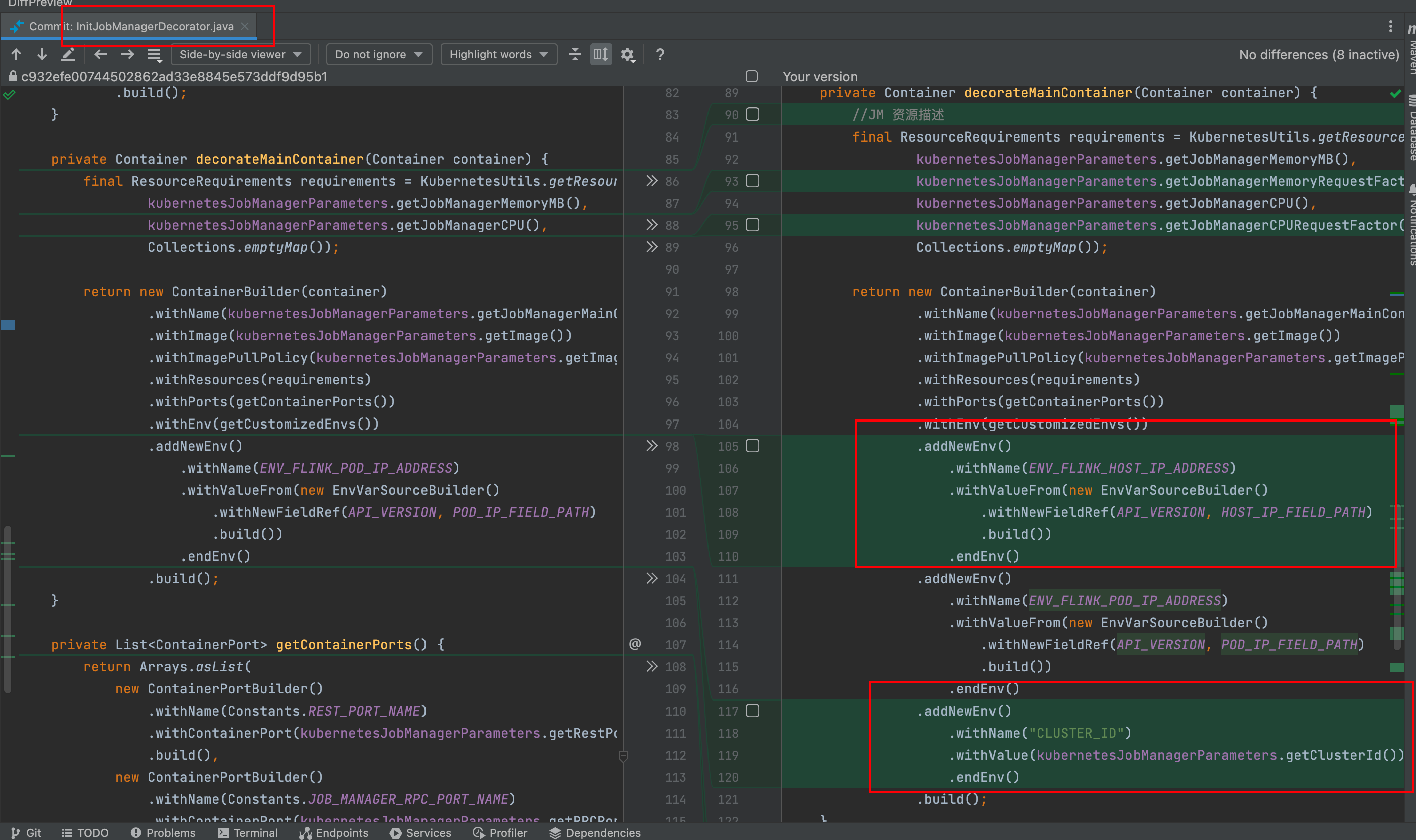
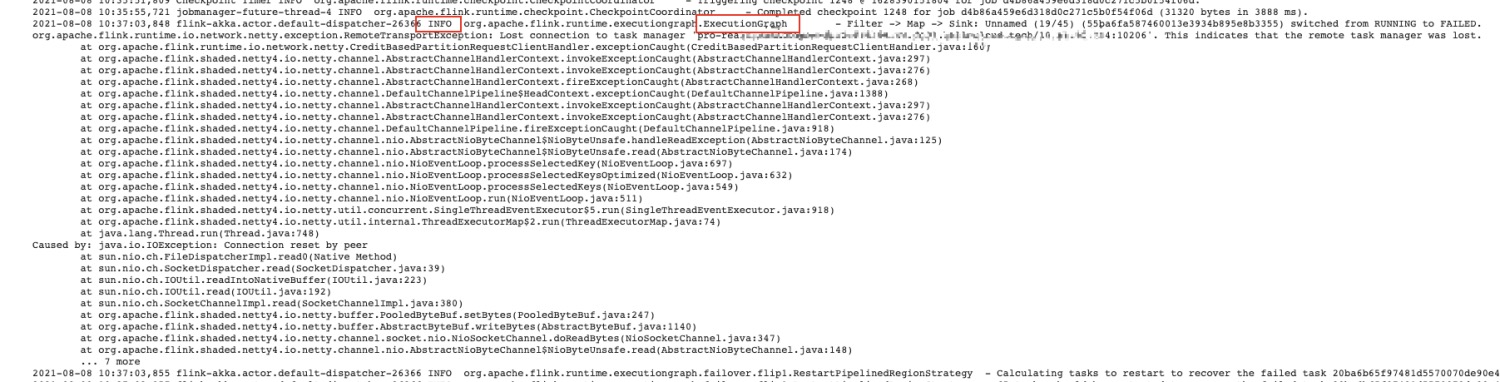
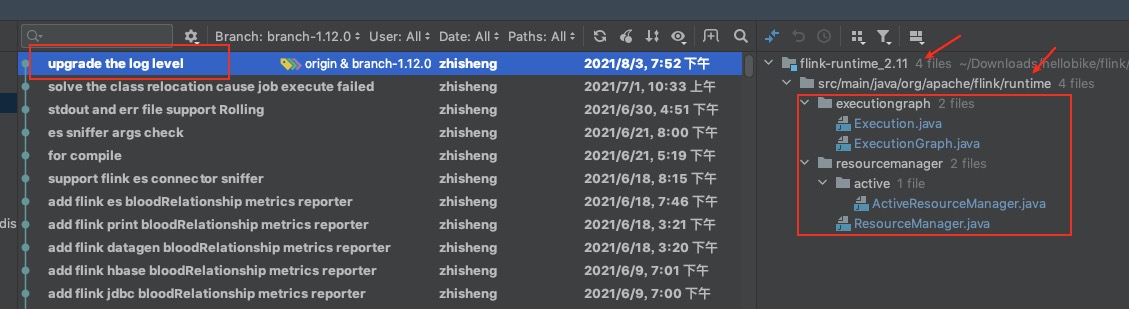
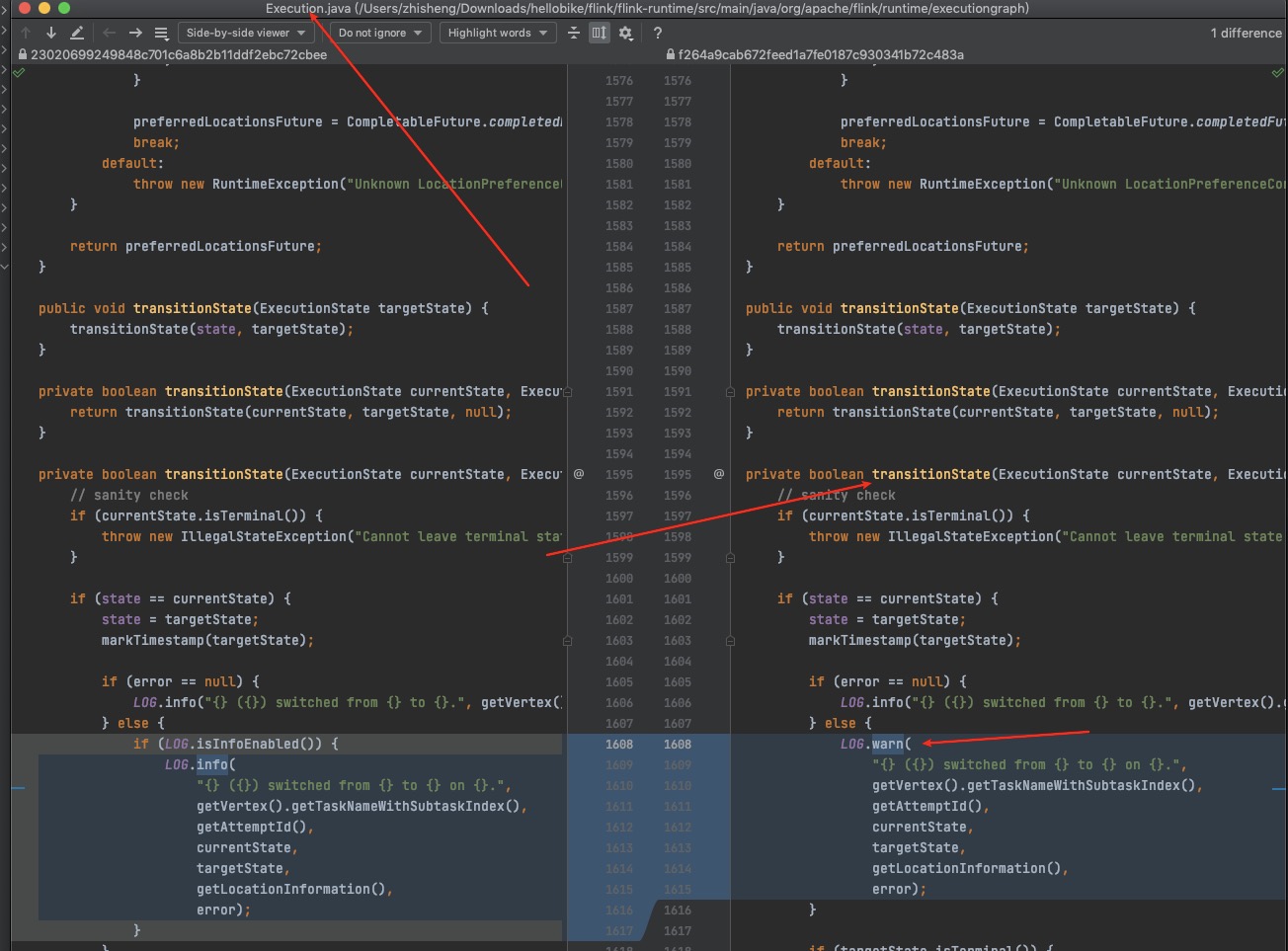
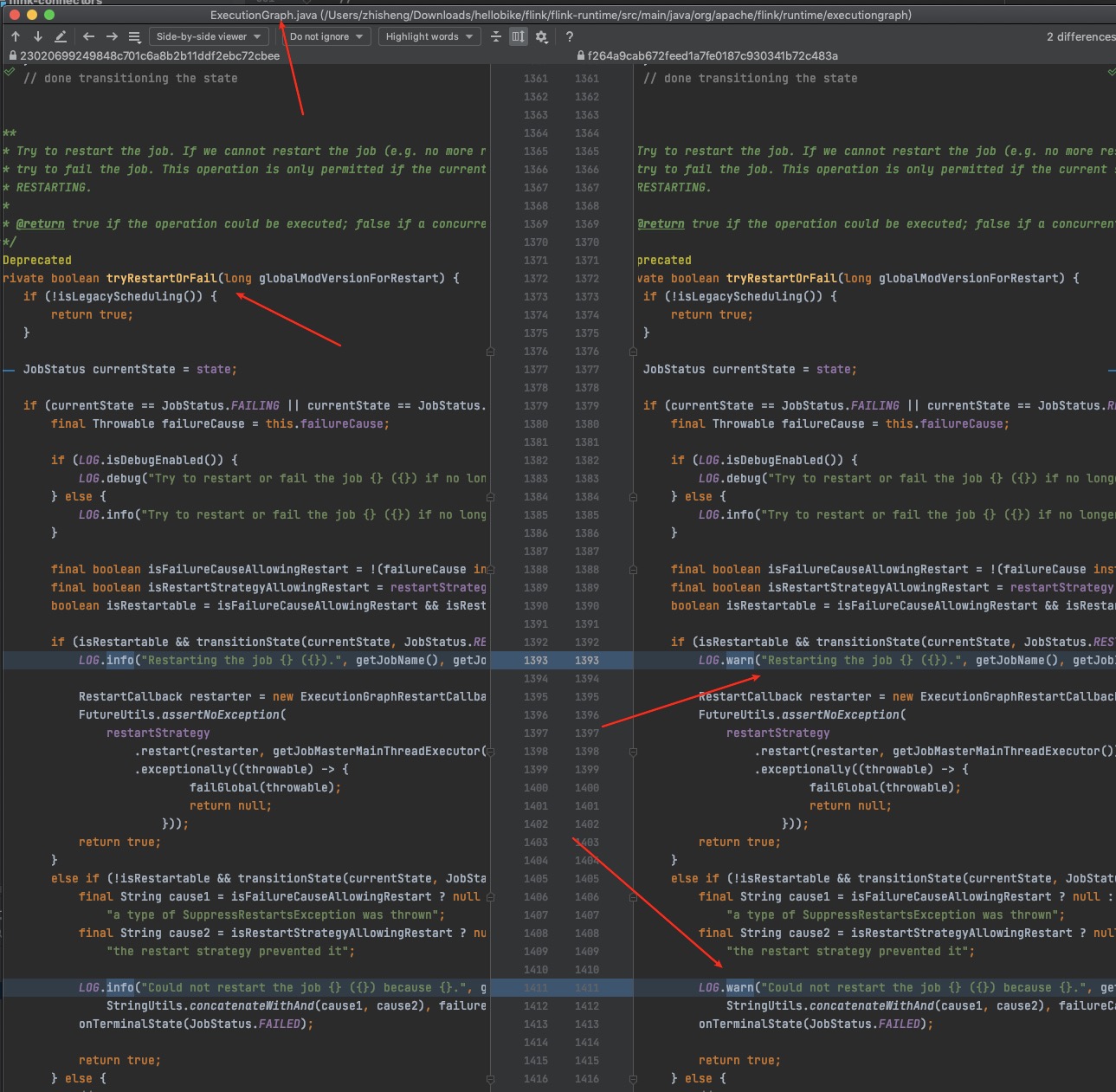
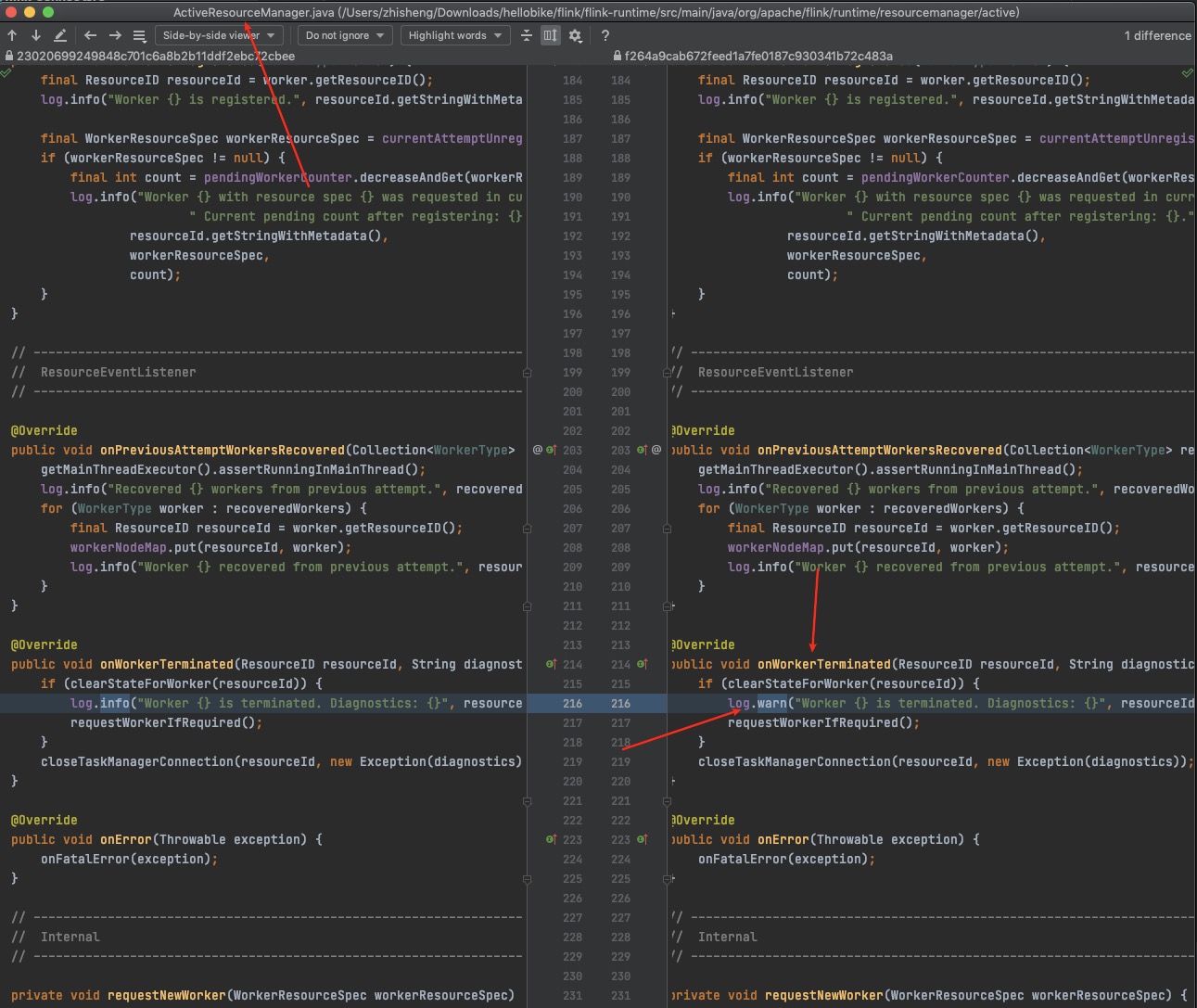
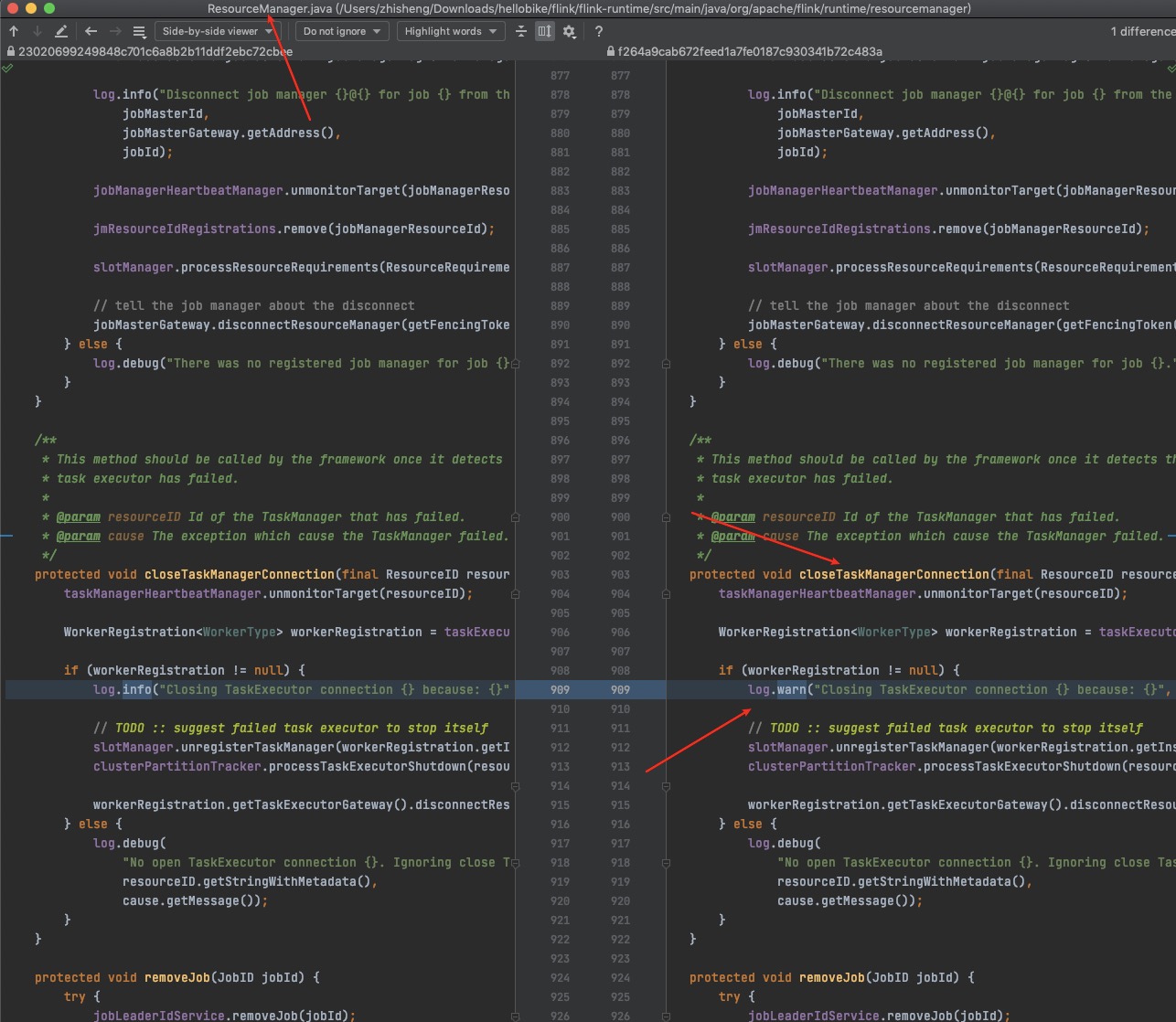
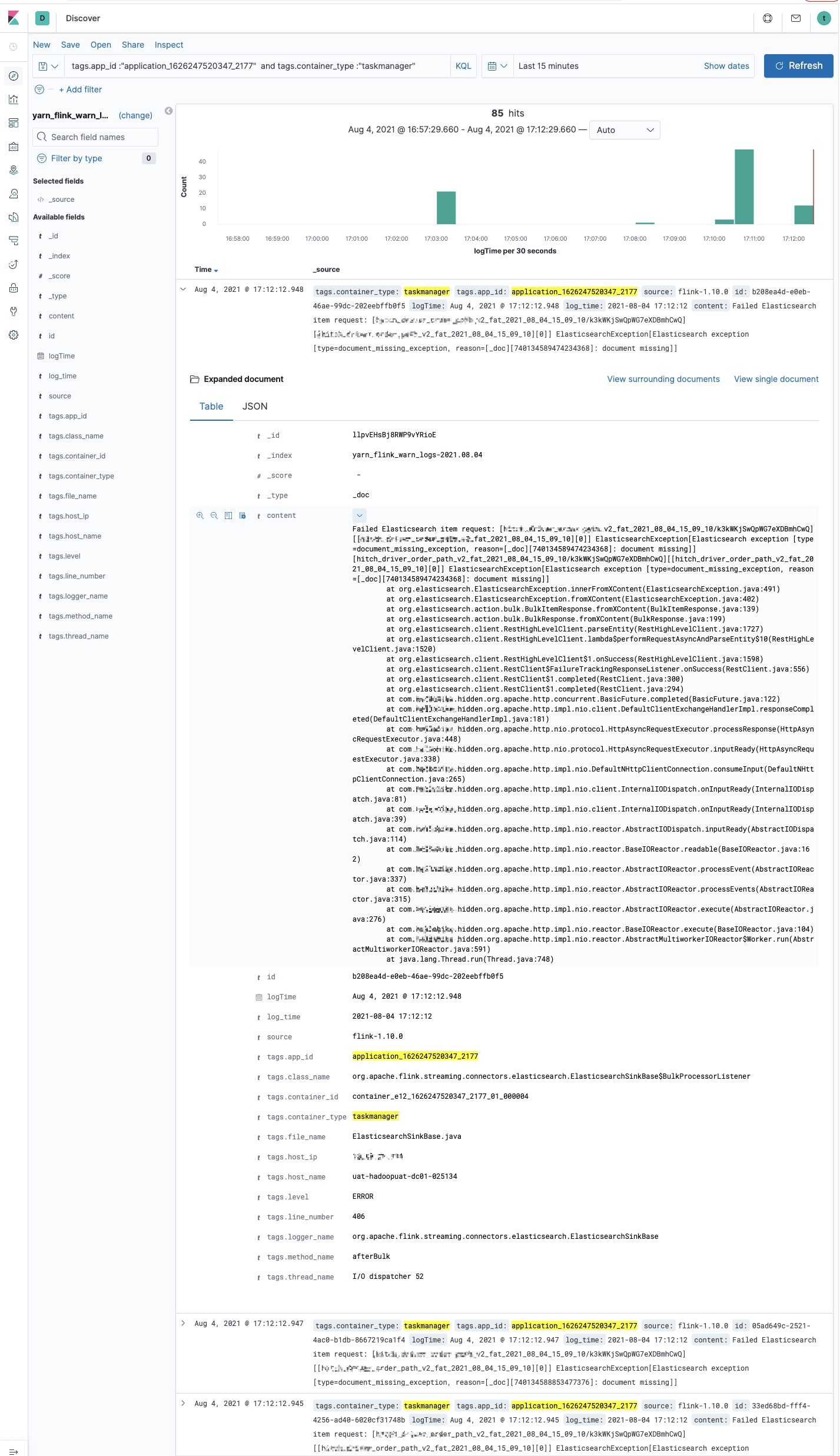
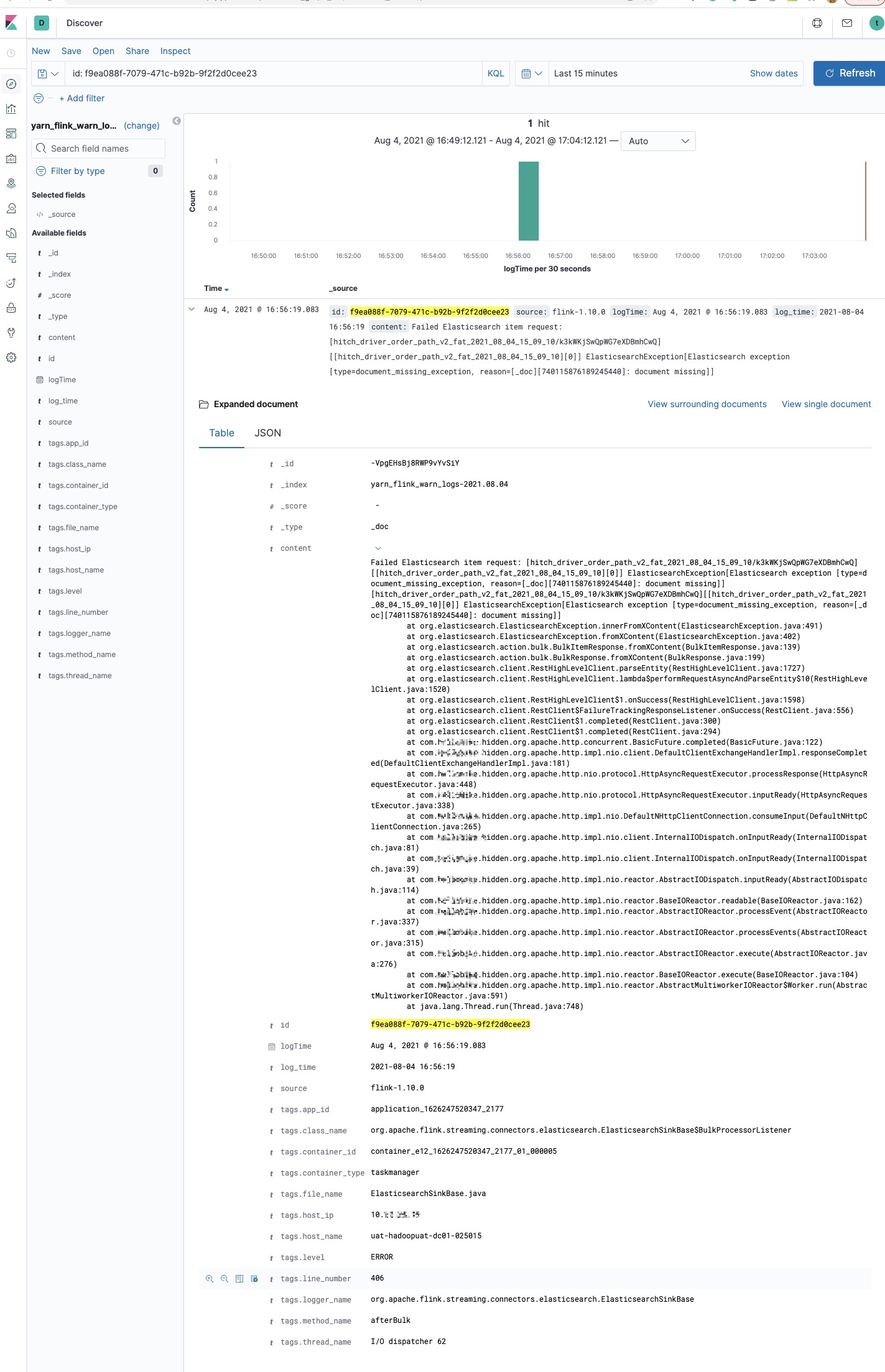
熟悉 Flink On K8s 的那更能体验到查看日志的痛苦了,在任务运行失败和结束后,所有的 Pod 都会退出,如果没有收集这些运行日志,那几乎很难知道任务为啥会失败。
Flink History Server 不像 Spark History Server 一样可以看到任务所有运行的 Excutor 日志,所以对于故障定位 Flink 任务异常日志这个场景,Flink 自带的那些体验不是很友好。因此也有本文的出现,来讲述一下如何针对上面两种运行模式下 Flink 任务的日志收集,来解决我们不方便定位任务异常失败的需求。
Properties props = new Properties(); for (Property property : properties) { props.put(property.getName(), property.getValue()); }
if (bootstrapServers != null) { props.setProperty("bootstrap.servers", bootstrapServers); } else { thrownew ConfigException("The bootstrap servers property must be specified"); } if (this.topic == null) { thrownew ConfigException("Topic must be specified by the Kafka log4j appender"); }
################################################################################ # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ################################################################################
# monitorInterval=30
# This affects logging for both user code and Flink rootLogger.level = INFO rootLogger.appenderRef.file.ref = MainAppender rootLogger.appenderRef.kafka.ref = KafkaLog4j2Appender
# Uncomment this if you want to _only_ change Flink's logging #logger.flink.name = org.apache.flink #logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on # log level INFO. The root logger does not override this. You have to manually # change the log levels here. logger.akka.name = akka logger.akka.level = INFO logger.kafka.name= org.apache.kafka logger.kafka.level = INFO logger.hadoop.name = org.apache.hadoop logger.hadoop.level = INFO logger.zookeeper.name = org.apache.zookeeper logger.zookeeper.level = INFO
Properties props = new Properties(); if (this.bootstrapServers != null) { props.setProperty("bootstrap.servers", this.bootstrapServers); } else { thrownew ConfigException("The bootstrap servers property must be specified"); } if (this.topic == null) { thrownew ConfigException("Topic must be specified by the Kafka log4j appender"); } if (this.source == null) { thrownew ConfigException("Source must be specified by the Kafka log4j appender"); }
# This affects logging for both user code and Flink log4j.rootLogger=INFO, RFA, kafka
# Uncomment this if you want to _only_ change Flink's logging #log4j.logger.org.apache.flink=INFO
# The following lines keep the log level of common libraries/connectors on # log level INFO. The root logger does not override this. You have to manually # change the log levels here. log4j.logger.akka=INFO log4j.logger.org.apache.kafka=INFO log4j.logger.org.apache.hadoop=INFO log4j.logger.org.apache.zookeeper=INFO
# Suppress the irrelevant (wrong) warnings from the Netty channel handler log4j.logger.org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline=ERROR, RFA
"kafka-producer-network-thread | application_1610962534438_1256_log" #11 daemon prio=5 os_prio=0 tid=0x00007f06394ad800 nid=0x27e waiting for monitor entry [0x00007f060be16000] java.lang.Thread.State: BLOCKED (on object monitor) at org.apache.log4j.Category.callAppenders(Category.java:205) - waiting to lock <0x00000000ffad7510> (a org.apache.log4j.spi.RootLogger) at org.apache.log4j.Category.forcedLog(Category.java:391) at org.apache.log4j.Category.log(Category.java:856) at org.slf4j.impl.Log4jLoggerAdapter.info(Log4jLoggerAdapter.java:324) at org.apache.kafka.clients.Metadata.update(Metadata.java:379) - locked <0x00000000ff1421d8> (a org.apache.kafka.clients.Metadata) at org.apache.kafka.clients.NetworkClient$DefaultMetadataUpdater.handleCompletedMetadataResponse(NetworkClient.java:1039) at org.apache.kafka.clients.NetworkClient.handleCompletedReceives(NetworkClient.java:822) at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:544) at org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:312) at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:235) at java.lang.Thread.run(Thread.java:748)
"Finalizer" #3 daemon prio=8 os_prio=0 tid=0x00007f06385f3800 nid=0x276 in Object.wait() [0x00007f0617c07000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000fff08ed0> (a java.lang.ref.ReferenceQueue$Lock) at j ava.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144) - locked <0x00000000fff08ed0> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:216)
Locked ownable synchronizers: - None
"Reference Handler" #2 daemon prio=10 os_prio=0 tid=0x00007f06385f1000 nid=0x275 in Object.wait() [0x00007f0617d08000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000fff06bf8> (a java.lang.ref.Reference$Lock) at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) - locked <0x00000000fff06bf8> (a java.lang.ref.Reference$Lock) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
Locked ownable synchronizers: - None
"main" #1 prio=5 os_prio=0 tid=0x00007f0638011800 nid=0x253 waiting for monitor entry [0x00007f063e7b7000] java.lang.Thread.State: BLOCKED (on object monitor) at org.apache.kafka.clients.Metadata.fetch(Metadata.java:129) - waiting to lock <0x00000000ff1421d8> (a org.apache.kafka.clients.Metadata) at org.apache.kafka.clients.producer.KafkaProducer.waitOnMetadata(KafkaProducer.java:960) at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:866) at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:846) at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:733) at com.zhisheng.log.appender.KafkaLog4jAppender.append(KafkaLog4jAppender.java:147) at org.apache.log4j.AppenderSkeleton.doAppend(AppenderSkeleton.java:251) - locked <0x00000000ff542900> (a com.zhisheng.log.appender.KafkaLog4jAppender) at org.apache.log4j.helpers.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:66) at org.apache.log4j.Category.callAppenders(Category.java:206) - locked <0x00000000ffad7510> (a org.apache.log4j.spi.RootLogger) at org.apache.log4j.Category.forcedLog(Category.java:391) at org.apache.log4j.Category.log(Category.java:856) at org.slf4j.impl.Log4jLoggerAdapter.warn(Log4jLoggerAdapter.java:401) at org.apache.hadoop.util.NativeCodeLoader.<clinit>(NativeCodeLoader.java:62) at org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback.<init>(JniBasedUnixGroupsMappingWithFallback.java:38) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133) at org.apache.hadoop.security.Groups.<init>(Groups.java:106) at org.apache.hadoop.security.Groups.<init>(Groups.java:101) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:449) - locked <0x00000000fec67710> (a java.lang.Class for org.apache.hadoop.security.Groups) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:327) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:294) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:854) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:824) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:693) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.util.EnvironmentInformation.getHadoopUser(EnvironmentInformation.java:96) at org.apache.flink.runtime.util.EnvironmentInformation.logEnvironmentInfo(EnvironmentInformation.java:293) at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(YarnJobClusterEntrypoint.java:96)
"VM Periodic Task Thread" os_prio=0 tid=0x00007f0638660000 nid=0x27d waiting on condition
JNI global references: 652
Found one Java-level deadlock: ============================= "kafka-producer-network-thread | application_1610962534438_1256_log": waiting to lock monitor 0x00007f0624005f18 (object 0x00000000ffad7510, a org.apache.log4j.spi.RootLogger), which is held by "main" "main": waiting to lock monitor 0x00007f06240047b8 (object 0x00000000ff1421d8, a org.apache.kafka.clients.Metadata), which is held by "kafka-producer-network-thread | application_1610962534438_1256_log"
Java stack information for the threads listed above: =================================================== "kafka-producer-network-thread | application_1610962534438_1256_log": at org.apache.log4j.Category.callAppenders(Category.java:205) - waiting to lock <0x00000000ffad7510> (a org.apache.log4j.spi.RootLogger) at org.apache.log4j.Category.forcedLog(Category.java:391) at org.apache.log4j.Category.log(Category.java:856) at org.slf4j.impl.Log4jLoggerAdapter.info(Log4jLoggerAdapter.java:324) at org.apache.kafka.clients.Metadata.update(Metadata.java:379) - locked <0x00000000ff1421d8> (a org.apache.kafka.clients.Metadata) at org.apache.kafka.clients.NetworkClient$DefaultMetadataUpdater.handleCompletedMetadataResponse(NetworkClient.java:1039) at org.apache.kafka.clients.NetworkClient.handleCompletedReceives(NetworkClient.java:822) at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:544) at org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:312) at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:235) at java.lang.Thread.run(Thread.java:748) "main": at org.apache.kafka.clients.Metadata.fetch(Metadata.java:129) - waiting to lock <0x00000000ff1421d8> (a org.apache.kafka.clients.Metadata) at org.apache.kafka.clients.producer.KafkaProducer.waitOnMetadata(KafkaProducer.java:960) at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:866) at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:846) at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:733) at com.zhisheng.log.appender.KafkaLog4jAppender.append(KafkaLog4jAppender.java:147) at org.apache.log4j.AppenderSkeleton.doAppend(AppenderSkeleton.java:251) - locked <0x00000000ff542900> (a com.zhisheng.log.appender.KafkaLog4jAppender) at org.apache.log4j.helpers.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:66) at org.apache.log4j.Category.callAppenders(Category.java:206) - locked <0x00000000ffad7510> (a org.apache.log4j.spi.RootLogger) at org.apache.log4j.Category.forcedLog(Category.java:391) at org.apache.log4j.Category.log(Category.java:856) at org.slf4j.impl.Log4jLoggerAdapter.warn(Log4jLoggerAdapter.java:401) at org.apache.hadoop.util.NativeCodeLoader.<clinit>(NativeCodeLoader.java:62) at org.apache.hadoop.security.JniBasedUnixGroupsMappingWithFallback.<init>(JniBasedUnixGroupsMappingWithFallback.java:38) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133) at org.apache.hadoop.security.Groups.<init>(Groups.java:106) at org.apache.hadoop.security.Groups.<init>(Groups.java:101) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:449) - locked <0x00000000fec67710> (a java.lang.Class for org.apache.hadoop.security.Groups) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:327) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:294) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:854) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:824) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:693) - locked <0x00000000fec436d0> (a java.lang.Class for org.apache.hadoop.security.UserGroupInformation) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.util.EnvironmentInformation.getHadoopUser(EnvironmentInformation.java:96) at org.apache.flink.runtime.util.EnvironmentInformation.logEnvironmentInfo(EnvironmentInformation.java:293) at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(YarnJobClusterEntrypoint.java:96)